
GraphRAG: Enhancing Retrieval-Augmented Generation with Structured Graph-Based Reasoning
GraphRAG: Enhancing Retrieval-Augmented Generation with Structured Graph-Based Reasoning
Problem Statement
Retrieval-Augmented Generation (RAG) has become a standard approach for reducing hallucinations in large language models by grounding responses in external knowledge sources. While effective for many tasks, conventional RAG systems exhibit a fundamental limitation: they rely heavily on semantic similarity between queries and text chunks. This makes them well-suited for retrieving localized facts but poorly equipped for handling queries that require understanding relationships across a dataset.
This limitation becomes especially apparent in domains with complex relational structures, such as medicine. For instance, when querying about a specific symptom, an ideal system should retrieve information about its causes, treatments, and related conditions. However, because these pieces of information are often distributed across different documents and connected through implicit relationships, traditional RAG systems may fail to retrieve them coherently. As a result, retrieval relevance degrades, even though the necessary information exists within the corpus.
Also, they struggle with queries that require aggregation of information across the dataset to compose an answer. Queries such as “What are the top 5 themes in the data?” perform terribly because baseline RAG relies on a vector search of semantically similar text content within the dataset. There is nothing in the query to direct it to the correct information.
Introduction
GraphRAG is proposed as a solution to these limitations. Instead of treating text as isolated chunks, it constructs a structured representation of the corpus in the form of a knowledge graph. In doing so, it leverages ideas from graph-based machine learning and network analysis, including community detection and graph traversal. This allows the system to move beyond simple similarity matching and toward relationship-aware reasoning.
In essence, GraphRAG reframes retrieval as a problem of navigating and summarizing a graph rather than selecting independent documents.
Content
RAGs are helping with reducing the hollucination of llms in different domains, but they still suffer from low retrieval relevancy/accuracy when it comes to relational data; for example, in medical domain, when we query about a specific symptom, we want to retrieve the most relevant information about that symptom, such as its causes, treatments, and related conditions. However, base rags may not always retrieve the most relevant information due to the complexity of the relationships between different pieces of information in the medical domain. GraphRAG offers unique advantages in capturing relational knowledge by leveraging graph/network analysis techniques (e.g., Graph Traversal Search and Community Detection).
Indexing
Text Chunks
Selecting the size of the chunk is a fundamental design decision; longer text chunks require fewer LLM calls for such extraction (which reduces cost) but suffer from degraded recall of information that appears early in the chunk.
Text Chunks → Entities & Relationships
We do this using a multipart LLM prompt that first identifies all entities in the text, including their name, type, and description, before identifying all relationships between clearly related entities, including the source and target entities and a description of their relationship. Both kinds of element instance are output in a single list of delimited tuples. The LLM can also be prompted to extract claims about detected entities. Claims are important factual statements about entities, such as dates, events, and interactions with other entities. 
To illustrate, suppose a chunk contained the following text:
1
2
3
4
NeoChip’s (NC) shares surged in their first week of trading on the NewTech Exchange. However, market analysts caution that the chipmaker’s public debut may
not reflect trends for other technology IPOs. NeoChip, previously a private entity,
was acquired by Quantum Systems in 2016. The innovative semiconductor firm
specializes in low-power processors for wearables and IoT devices.
The LLM is prompted such that it extracts the following:
Entities:
- NeoChip, with description “NeoChip is a publicly traded company specializing in low-power processors for wearables and IoT devices.”
- Quantum Systems, with description “Quantum Systems is a firm that previously owned NeoChip.”
Relationships:
- NeoChip → Quantum Systems: “Quantum Systems owned NeoChip from 2016 until NeoChip became publicly traded.”
Claims:
- NeoChip’s shares surged during their first week of trading on the NewTech Exchange.
- NeoChip debuted as a publicly listed company on the NewTech Exchange.
- Quantum Systems acquired NeoChip in 2016 and held ownership until NeoChip went public.
These prompts can be tailored to the domain of the document corpus by choosing domain appropriate few-shot exemplars for in-context learning. Self-reflection is a prompt engineering technique where the LLM generates an answer, and is then prompted to evaluate its output for correctness, clarity, or completeness, then finally generate an improved response based on that evaluation. We leverage self-reflection in knowledge graph extraction, and explore ways how removing self-reflection affects performance and cost. 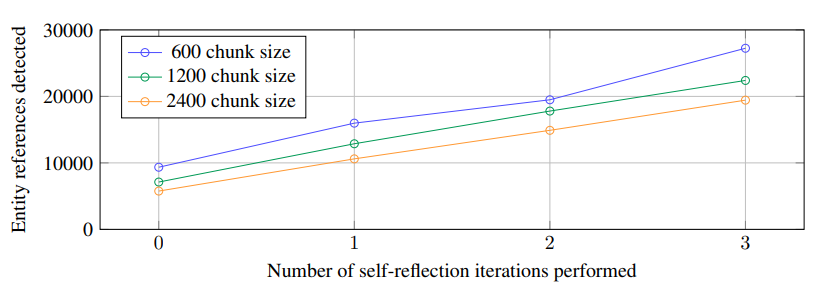
Entities & Relationships → Knowledge Graph
The entity/relationship/claim extraction processes creates multiple instances of a single element because an element is typically detected and extracted multiple times across documents. In the final step of the knowledge graph extraction process, these instances of entities and relationships become individual nodes and edges in the graph. Entity descriptions are aggregated and summarized for each node and edge. Relationships are aggregated into graph edges, where the number of duplicates for a given relationship becomes edge weights. Claims are aggregated similarly. In this manuscript, our analysis uses exact string matching for entity matching (the task of reconciling different extracted names for the same entity). However, softer matching approaches can be used with minor adjustments to prompts or code. Furthermore, GraphRAG is generally resilient to duplicate entities since duplicates are typically clustered together for summarization in subsequent steps.
Knowledge Graph → Graph Communities
- In our pipeline, we use Leiden community detection in a hierarchical manner, recursively detecting sub-communities within each detected community until reaching leaf communities that can no longer be partitioned.
1
Leiden community detection is an iterative graph clustering algorithm that groups nodes by maximizing modularity—meaning it prefers communities where nodes are more densely connected than would be expected by chance (based on node degrees). It starts by assigning each node to its own community, then repeatedly moves each node to the neighboring community that gives the highest modularity gain—i.e., where its connections are stronger than expected under a random graph with the same degree distribution. After this local movement phase, Leiden adds a crucial refinement step to ensure that each community is internally well-connected (fixing issues present in Louvain), then aggregates each community into a super-node to form a smaller graph and repeats the process hierarchically until no further improvement is possible, resulting in stable, coherent, and multi-level communities.
- implemented using the graspologic library.
Graph Communities → Community Summaries
GraphRAG generates community summaries by adding various element summaries (for nodes, edges, and related claims) to a community summary template. Community summaries from lower-level communities are used to generate summaries for higher-level communities.
Output Artifacts
1
2
3
4
5
6
7
8
project/
└── output/
├── create_base_text_units.parquet
├── create_final_entities.parquet
├── create_final_relationships.parquet
├── create_final_communities.parquet
├── create_final_community_reports.parquet
└── lancedb/ ### Vector store
A Parquet file is a columnar storage format; meaning it stores data by columns instead of by rows like CSV files.
Query
Global Search
Given a user query, the community summaries at a certain level can be used to generate a final answer in a multi-stage process. The hierarchical nature of the community structure also means that questions can be answered using the community summaries from different levels. first we answer to the question in parallel using each community summary(map) along with the a helpfulness score, then elaborate the most helpful answers to generate final answer(reduce). the community level is pre-defined, but can be chosen dynamically. For this matter, We first ask the LLM to rate how relevant each level 0 community is with respect to the user query, we then traverse down the child node(s) if the current community report is deemed relevant. 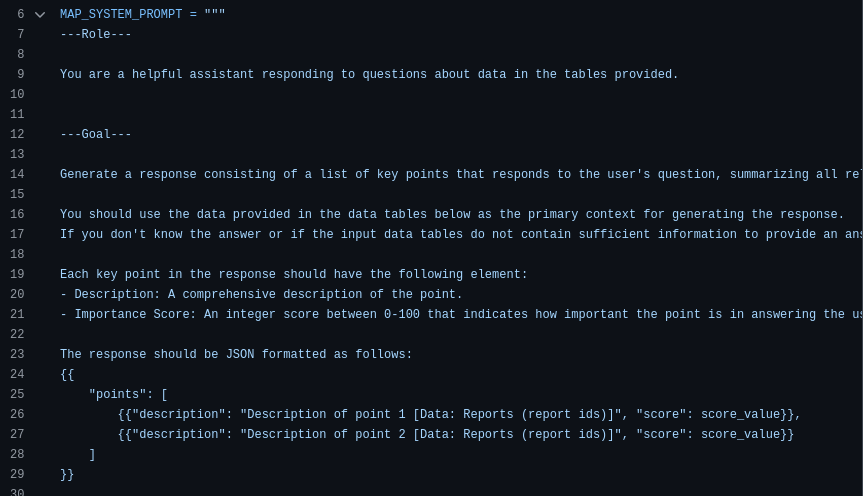 Figure: Map phase
Figure: Map phase
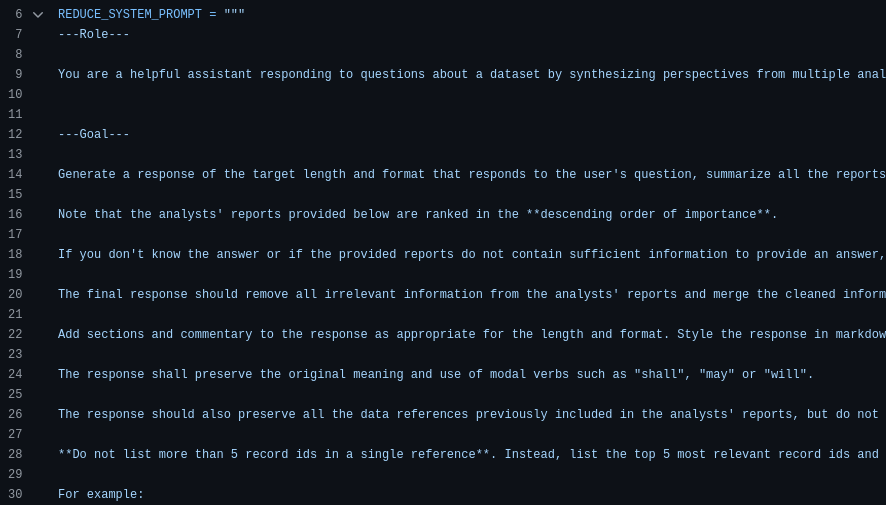 Figure: Reduce phase
Figure: Reduce phase
Local search
when searching for specific information about a particular entity, we can use this type of search. In indexing time, beside of graph construction, we also create a vector store of entity descriptions. So here, we can use the query to retrieve the most relevant entities, then related relationships, text chunks, and community reports are gathered, then prioritized and filtered to fit within a single context window of pre-defined size(proportion of each is configurable), to generate the final answer.
DRIFT Search
DRIFT search introduces a hybrid approach that combines the strengths of both global and local search methods. It operates in three core phases:
Phase 1: Primer
- High-Level Summaries: It gathers pre-computed “Community Reports” using HyDE (Hypothetical Document Embeddings) that are most relevant to your query.
1
HyDE picks a random community report to use as a structural template. It then asks the LLM to generate a hypothetical, fake answer to the user's query that mimics the format of that template. Then uses this hypothetical answer to retrieve the most relevant community reports.
- The Foundation: It feeds these summaries to the LLM and asks it to do three things:
- Draft a comprehensive but broad initial answer.
- Score how well this answer actually solves your prompt.
- Generate a list of highly specific follow-up questions to investigate the gaps, missing details, or interesting angles discovered in the broad answer.
- The Starting Point: This creates the “root” of a dynamic search tree.
Phase 2: Follow-up
This is where the “Dynamic Reasoning” happens. The system enters a loop, acting like a researcher digging through archives based on clues.
- Prioritizing Questions: The system looks at all the unanswered follow-up questions generated in the previous step and ranks them to figure out which ones are most promising.
- Granular Search: For the top questions it performs Local Search.
- Branching Out: For every question it investigates, the LLM generates a specific “intermediate-answer” based on the raw data. Crucially, based on what it just learned, it generates even more follow-up questions.
Phase 3: Output Hierarchy
Once the system has hit its limit for how deep it should dig, it has a massive, messy web of both broad overviews and highly specific, granular details.
- Gathering the Pieces: The system collects every successful “intermediate answer” it generated along the way, from the broad primer answer to the deeply specific answers found at the bottom of the search tree.
- The Final Polish: It takes this entire collection of context and feeds it back to the LLM one last time, alongside your original prompt. Behind the scenes, the system also preserves the “map” of how it found this information, in case the user interface wants to show the steps it took to get there.
DRIFT search is more computationally intensive than either local or global search alone, as it combines both approaches with iterative refinement.
Graph Analysis Example
This is a graph analysis of a sample book named “A Christmas Carol” by Charles Dickens indexed by this framework: 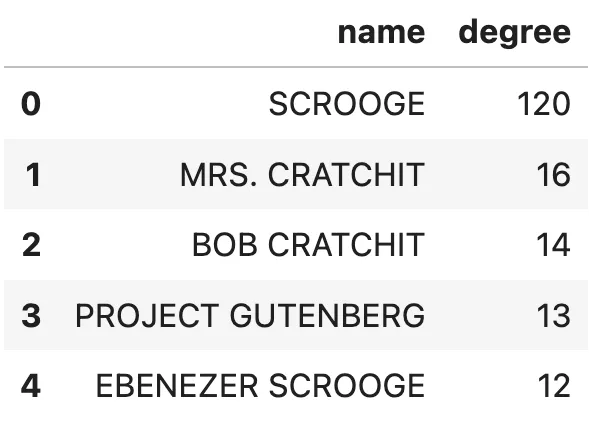 Entities with the most relationships. Image by author.
Entities with the most relationships. Image by author.
Without any hesitation, we can assume that Scrooge is the book’s main character. I would also venture a guess that Ebenezer Scrooge and Scrooge are actually the same entity, but as the MSFT GraphRAG lacks an entity resolution step, they weren’t merged.
It also shows that analyzing and cleaning the data is a vital step to reducing noise information, as Project Gutenberg has 13 relationships, even though they are not part of the book story.
Final Notes
- They conducted an experiment where they compared the Global Search’s comperhensiveness and diversity of different community levels(C0-C3), naive rag(SS), and hierarchical text summarization(TS). In summary we can say that the intermediate community levels outperformed other configurations: C2 ≈ C3 ≥ C1 > C0 ≈ TS » SS
- What GraphRAG is really buying you vs Hierarchical text summarization is: semantic partitioning before summarization But it comes with a cost:
| Approach | Cost | Quality |
|---|---|---|
| Hierarchical text summarization | low | decent |
| GraphRAG | high (indexing expensive) | better global reasoning |
The paper even shows: Graph indexing took ~281 minutes for ~1M tokens
- The paper literally suggests hybrid approaches: combine embedding-based retrieval with graph-based summaries
- You should note that the implementation of GraphRAG by MSFT is not optimized for production use. For instance, the output of the indexing phase is some parquet files and a vector store, which it loads all of them in memory for inferencing(which is not scalable for large corpora). Although, this notebook shows you how to import the output artifacts into a Neo4j graph database, which is more suitable for production use.
- Also this blog provides implementations for global and local search using Neo4j graph database.